



These days the internet is being widely used than it was used a few years back. It has become a core part of our life. Billions of people are using social media and social networking every day all across the globe. Such a huge number of people generate a flood of data which have become quite complex to manage. Considering this enormous data, a term has been coined to represent it.
So, what is this term called?
Yes, Big Data
Big Data is the term coined to refer to this huge amount of data. The concept of big data is fast spreading its arms all over the world. It is a trending topic for thesis, project, research, and dissertation. There are various good topics for the master’s thesis and research in Big Data and Hadoop as well as for Ph.D. First of all know, what is big data and Hadoop?
Find the link at the end to download the latest thesis and research topics in Big Data
What is Big Data?
Big Data refers to the large volume of data which may be structured or unstructured and which make use of certain new technologies and techniques to handle it. An organized form of data is known as structured data while an unorganized form of data is known as unstructured data. The data sets in big data are so large and complex that we cannot handle them using traditional application software. There are certain frameworks like Hadoop designed for processing big data. These techniques are also used to extract useful insights from data using predictive analysis, user behavior, and analytics. You can explore more on big data introduction while working on the thesis in Big Data. Big Data is defined by three Vs:
Volume – It refers to the amount of data that is generated. The data can be low-density, high volume, structured/unstructured or data with unknown value. This unknown data is converted into useful one using technologies like Hadoop. The data can range from terabytes to petabytes.
Velocity – It refers to the rate at which the data is generated. The data is received at an unprecedented speed and is acted upon in a timely manner. It also requires real-time evaluation and action in case of the Internet of Things(IoT) applications.
Variety – Variety refers to different formats of data. It may be structured, unstructured or semi-structured. The data can be audio, video, text or email. In this additional processing is required to derive the meaning of data and also to support the metadata.
In addition to these three Vs of data, following Vs are also defined in big data.
Value – Each form of data has some value which needs to be discovered. There are certain qualitative and quantitative techniques to derive meaning from data. For deriving value from data, certain new discoveries and techniques are required.
Variability – Another dimension for big data is the variability of data i.e the flow of data can be high or low. There are challenges in managing this flow of data.
Thesis Research Topics in Big Data
- Privacy, Security Issues in Big Data.
- Storage Systems of Scalable for Big Data.
- Massive Big Data Processing of Software and Tools.
- Techniques and Data Mining Tools for Big Data.
- Big Data Adoptation and Analytics of Cloud Computing Platforms.
- Scalable Architectures for Parallel Data Processing.
Can you imagine how big is big data?
Of course, you can’t.
The amount of big data that is generated and stored on a global scale is unbelievable and is growing day by day. But do you know, only a small portion of this data is actually analyzed mainly for getting useful insights and information?
Big Data Hadoop
Hadoop is an open-source framework provided to process and store big data. Hadoop makes use of simple programming models to process big data in a distributed environment across clusters of computers. Hadoop provides storage for a large volume of data along with advanced processing power. It also gives the ability to handle multiple tasks and jobs.
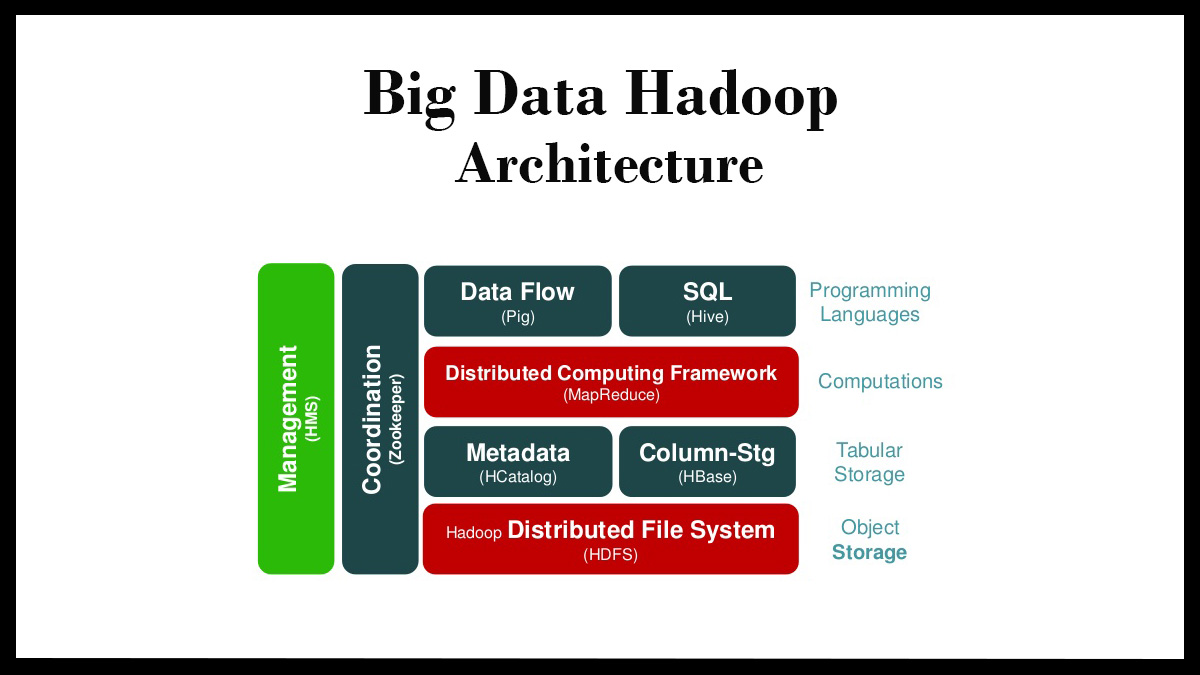
Big Data Hadoop Architecture
HDFS is the main component of Hadoop architecture. It stands for Hadoop Distributed File Systems. It is used to store a large amount of data and multiple machines are used for this storage. MapReduce Overview is another component of big data architecture. The data is processed here in a distributed manner across multiple machines. YARN component is used for data processing resources like CPU, RAM, and memory. Resource Manager and Node Manager are the elements of YARN. These two elements work as master and slave. Resource Manager is the master and assigns resources to the slave i.e. Node Manager. Node Manager sends the signal to the master when it is going to start the work. Big Data Hadoop for the thesis will be plus point for you.
Importance of Hadoop in big data
Hadoop is essential especially in terms of big data. The importance of Hadoop is highlighted in the following points:
Processing of huge chunks of data – With Hadoop, we can process and store huge amount of data mainly the data from social media and IoT(Internet of Things) applications.
Computation power – The computation power of Hadoop is high as it can process big data pretty fast. Hadoop makes use of distributed models for processing of data.
Fault tolerance – Hadoop provide protection against any form of malware as well as from hardware failure. If a node in the distributed model goes down, then other nodes continue to function. Copies of data are also stored.
Flexibility – As much data as you require can be stored using Hadoop. There is no requirement of preprocessing the data.
Low Cost – Hadoop is an open-source framework and free to use. It provides additional hardware to store the large quantities of data.
Scalability – The system can be grown easily just by adding nodes in the system according to the requirements. Minimal administration is required.
Challenges of Hadoop
No doubt Hadoop is a very good platform for big data solution, still, there are certain challenges in this.
These challenges are:
- All problems cannot be solved – It is not suitable for iteration and interaction tasks. Instead, it is efficient for simple problems for which division into independent units can be made.
- Talent Gap – There is a lack of talented and skilled programmers in the field of MapReduce in big data especially at entry level.
- Security of data – Another challenge is the security of data. Kerberos authentication protocol has been developed to provide a solution to data security issues.
- Lack of tools – There is a lack of tools for data cleaning, management, and governance. Tools for data quality and standardization are also lacking.
Fields under Big Data
Big Data is a vast field and there are a number of topics and fields under it on which you can work for your thesis, dissertation as well as for research. Big Data is just an umbrella term for these fields.
Search Engine Data – It refers to the data stored in the search engines like Google, Bing and is retrieved from different databases.
Social Media Data – It is a collection of data from social media platforms like Facebook, Twitter.
Stock Exchange Data – It is a data from companies indulged into shares business in the stock market.
Black box Data – Black Box is a component of airplanes, helicopters for voice recording of fight crew and for other metrics.
Big Data Technologies
Big Data technologies are required for more detailed analysis, accuracy and concrete decision making. It will lead to more efficiency, less cost, and less risk. For this, a powerful infrastructure is required to manage and process huge volumes of data.
The data can be analyzed with techniques like A/B Testing, Machine Learning, and Natural Language Processing.
The big data technologies include business intelligence, cloud computing, and databases.
The visualization of data can be done through the medium of charts and graphs.
Multi-dimensional big data can be handled through tensor-based computation. Tensor-based computation makes use of linear relations in the form of scalars and vectors.
Other technologies that can be applied to big data are:
Massively Parallel Processing
Search based applications
Data Mining
Distributed databases
Cloud Computing
These technologies are provided by vendors like Amazon, Microsoft, IBM etc to manage the big data.
MapReduce Algorithm for Big Data
A large amount of data cannot be processed using traditional data processing approaches. This problem has been solved by Google using an algorithm known as the MapReduce algorithm. Using this algorithm, the task can be divided into small parts and these parts are assigned to distributed computers connected on the network. The data is then collected from individual computers to form a final dataset.
The MapReduce algorithm is used by Hadoop to run applications in which parallel processing of data is done on different nodes. Hadoop framework can develop applications that can run on clusters of computers to perform statistical analysis of a large amount of data.
The MapReduce algorithm consist of two tasks:
Map
Reduce
A set is of data is taken by Map which is converted into another set of data in which individual elements are broken into pairs known as tuples. Reduce takes the output of Map task as input. It combines data tuples into smaller tuples set.
Algorithm
The MapReduce algorithm is executed in three stages:
Map
Shuffle
Reduce
In the map stage, the input data is processed and stored in the Hadoop file system(HDFS). After this a mapper performs the processing of data to create small chunks of data. Shuffle stage and Reduce stage occur in combination. The Reducer takes the input from the mapper for processing to create a new set of output which will later be stored in the HDFS.
The Map and Reduce tasks are assigned to appropriate servers in the cluster by the Hadoop. The Hadoop framework manages all the details like issuing of tasks, verification, and copying. After completion, the data is collected at the Hadoop server. You can get thesis and dissertation guidance for the thesis in Big Data Hadoop from data analyst.
Applications of Big Data
Big Data find its application in various areas including retail, finance, digital media, healthcare, customer services etc.
Government
Big Data is used within governmental services with efficiency in cost, productivity, and innovation. The common example of this is the Indian Elections of 2014 in which BJP tried this to win the elections. The data analysis, in this case, can be done by the collaboration between the local and the central government. Big Data was the major factor behind Barack Obama’s win in the 2012 election campaign.
Finance
Big Data is used in finance for market prediction. It is used for compliance and regulatory reporting, risk analysis, fraud detection, high-speed trading and for analytics. The data which is used for market prediction is known as alternate data.
Healthcare
Big Data is used in health care services for clinical data analysis, disease pattern analysis, medical devices and medicines supply, drug discovery and various other such analytics. Big Data analytics have helped in a major way in improving the healthcare systems. Using these certain technologies have been developed in healthcare systems like eHealth, mHealth, and wearable health gadgets.
Media
Media uses Big Data for various mechanisms like ad targeting, forecasting, clickstream analytics, campaign management and loyalty programs. It is mainly focused on following three points:
Targeting consumers
Capturing of data
Data journalism
Big Data is a core of IoT(Internet of Things). They both work together. Data can be extracted from IoT devices for mapping which helps in interconnectivity. This mapping can be used to target customers and for media efficiency by the media industry.
Information Technology
Big Data has helped employees working in Information Technology to work efficiently and for widespread distribution of Information Technology. Certain issues in Information Technology can also be resolved using Big Data. Big Data principles can be applied to machine learning and artificial intelligence for providing better solutions to the problems.
Advantages of Big Data
Big Data has certain advantages and benefits, particularly for big organizations.
- Time Management – Big data saves valuable time as rather than spending hours on managing the different amount of data, big data can be managed efficiently and at a faster pace.
- Accessibility – Big Data is easily accessible through authorization and data access rights and privileges.
- Trustworthy – Big Data is trustworthy in the sense that we can get valuable insights from the data.
- Relevant – The data is relevant whereas irrelevant data require filtering which can lead to complexity.
- Secure – The data is secured using data hosting and through various advanced technologies and techniques.
Challenges of Big Data
Although Big Data has come in a big way in improving the way we store data, there are certain challenges which need to be resolved.
- Data Storage and quality of Data – The data is growing at a fast pace as the number of companies and organizations are growing. Proper storage of this data has become a challenge. This data can be stored in data warehouses but this data is inconsistent. There are issues of errors, duplicacy, conflicts while storing this data in their native format. Moreover, this changes the quality of data.
- Lack of big data analysts – There is a huge demand for data scientists and analysts who can understand and analyze this data. But there are very few people who can work in this field considering the fact that huge amount of data is produced every day. Those who are there don’t have proper skills.
- Quality Analysis – Big companies and organizations use big for getting useful insights to make proper decisions for future plans. The data should also be accurate as inaccurate data can lead to wrong decisions that will affect the company business. Therefore quality analysis of the data should be there. For this testing is required which is a time-consuming process and also make use of expensive tools.
- Security and Privacy of Data – Security, and privacy are the biggest risks in big data. The tools that are used for analyzing, storing, managing use data from different sources. This makes data vulnerable to exposure. It increases security and privacy concerns.
Thus Big Data is providing a great help to companies and organizations to make better decisions. This will ultimately lead to more profit. The main thesis topics in Big Data and Hadoop include applications, architecture, Big Data in IoT, MapReduce, Big Data Maturity Model etc.
Latest Thesis and Research Topics in Big Data
There are a various thesis and research topics in big data for M.Tech and Ph.D. Following is the list of good topics for big data for masters thesis and research:
- Big Data Virtualization
- Internet of Things(IoT)
- Big Data Maturity Model
- Data Science
- Data Federation
- Sampling
- Big Data Analytics
- Clustering
- SQL-on-Hadoop
- Predictive Analytics
Big Data Virtualization
Big Data Virtualization is the process of creating virtual structures rather than actual for Big Data systems. It is very beneficial for big enterprises and organizations to use their data assets to achieve their goals and objectives. Virtualization tools are available to handle big data analytics.
Internet of Things(IoT)
Big Data and IoT work in coexistence with each other. IoT devices capture data which is extracted for connectivity of devices. IoT devices have sensors to sense data from its surroundings and can act according to its surrounding environment.
Big Data Maturity Model
Big Data Maturity Models are used to measure the maturity of big data. These models help organizations to measure big data capabilities and also assist them to create a structure around that data. The main goal of these models is to guide organizations to set their development goals.
Data Science
Data Science is more or less related to Data Mining in which valuable insights and information are extracted from data both structured and unstructured. Data Science employs techniques and methods from the fields of mathematics, statistics, and computer science for processing.
Data Federation
Data Federation is the process of collecting data from different databases without copying and without transferring the original data. Rather than whole information, data federation collects metadata which is the description of the structure of original data and keep them in a single database.
Sampling
Sampling is a technique of statistics to find and locate patterns in Big Data. Sampling makes it possible for the data scientists to work efficiently with a manageable amount of data. Sampled data can be used for predictive analytics. Data can be represented accurately when a large sample of data is used.
Big Data Analytics
It is the process of exploring large datasets for the sake of finding hidden patterns and underlying relations for valuable customer insights and other useful information. It finds its application in various areas like finance, customer services etc. It is a good choice for Ph.D. research in big data analytics.
Clustering
Clustering is a technique to analyze big data. In clustering, a group of similar objects is grouped together according to their similarities and characteristics. In other words, this technique partitions the data into different sets. The partitioning can be hard partitioning and soft partitioning. There are various algorithms designed for big data and data mining. It is a good area for thesis and researh in big data.
SQL-on-Hadoop
SQL-on-Hadoop is a methodology for implementing SQL on Hadoop platform by combining together the SQL-style querying system to the new components of the Hadoop framework. There are various ways to execute SQL in Hadoop environment which include – connectors for translating the SQL into a MapReduce format, push down systems to execute SQL in Hadoop clusters, systems that distribute the SQL work between MapReduce – HDFS clusters and raw HDFS clusters. It is a very good topic for thesis and research in Big Data.
Predictive Analytics
It is a technique of extracting information from the datasets that already exist in order to find out the patterns and estimate future trends. Predictive Analytics is the practical outcome of Big Data and Business Intelligence(BI). There are predictive analytics models which are used to get future insights. For this future insight, predictive analytics take into consideration both current and historical data. It is also an interesting topic for thesis and research in Big Data.
These were some of the good topics for big data for M.Tech and masters thesis and research work. For any help on thesis topics in Big Data, contact Techsparks. Call us on this number 91-9465330425 or email us at techsparks2013@gmail.com for M.Tech and Ph.D. help in big data thesis topics.
Click on the following link to download the latest thesis and research topics in Big Data
Latest Thesis and Research Topics in Big Data(pdf)